 |
SoftTree Technologies
Technical Support Forums
|
|
| Author |
Message |
gemisigo
Joined: 11 Mar 2010
Posts: 2170
|
|
 FR: Scratchpad FR: Scratchpad |
 |
We had a discussion about the support (or more precisely, the absence of it) for remembered session settings and you offered a pretty good way for changing them here. This is a fine example of how SA can be extended to suit the different needs and requirements. But it still leaves without an easy and convenient way for showing the actual values for those session settings. Yes, we can always query for those things but that method lacks in the "convenient" department).
At first, I was thinking about asking for some indicators to be shown on the status bar, but there are already a couple of things displayed there and to be honest, showing a list in a horizontal layout is not a very good idea. Then I remembered another feature I was yearning for, well, for a very long time. But it takes some effort to describe my idea and I was always a tad lazy. Now I'll try and you decide if it was worth it or not.
Many times when we're testing system parts using a database the scenario is the following: a group of people goes through the pre-defined test cases by invoking different parts of the system (usually running some applications or trying some features of said applications) and another small set of people watches the state of the database.
Now, that "watching the database" part is sometimes a quite complex job involving multiple queries. If that's the case, and especially if that test is expected to be repeated in the future, it's a sane thing to write a reusable unit test, that conveniently returns an 'OK' or a 'you are a pathetic excuse for a database developer'.
Other times, the test case requires changing some parameters for each test run and the result sets are not that easy to evaluate (we simply have to see the data). Also, the task of constantly changing those parameters in the Initialize or Execute tabs and trying to write the query that could evaluate the results so that it could pass a single result for the Unit Testing / Check / Result to compare but still can tell which part has problems takes a considerable amount of extra effort, is overly complicated, error-prone and simply not worth it. In those cases, we fall back to using ad-hoc queries that are run in SE and we check the result sets in the Results pane using our Mark I eyeballs (also error-prone). We change, select, and execute the queries that set the parameters. Then we select one or multiple sets of the queries and then crawl through the result tabs, one by one, even if that result set is a one-row-one-column table, that is, a simple value. Things get worse when those values are meaningless when standing alone and have to be evaluated together with other values. We have to switch constantly back and forth between the result tabs. So why not combine those into a single result set. It quickly turned out that simple
 |
 |
SELECT xyz AS my_interesting_value
|
statements no longer yielded interpretable value when you UNION-ed them. So that intuitively looking code has to be rewritten into something much less intuitive like this
|
|
SELECT 'my value name' AS value_name, xyz AS actual_value
UNION
...
|
Also, this works on MariaDB:
|
|
SELECT 'my value name' AS value_name, 'xyz' AS actual_value
UNION
SELECT 'my other value name' AS value_name, 2 AS actual_value
|
Now good luck running it on an SQL Server without casting the actual value column for each row. So we abandoned the whole concept completely.
This lead to the idea of the Scratchpad. A list (set, array, whatever) of arbitrarily complex queries that are each run in the defined order after the contents of the editor, each yield a single-row-single-column table which is then converted into two-column (value name, value "value") tables (like the above), UNION-ed together, and shown as a single result set, could construct a Scratchpad. But I never took the time to draw it up as a feature request because I wasn't sure others would find it interesting. Now, that even after five years of the original idea we constantly end up with our tests eerily reminiscent of the same "template", I'm not so sure about it.
I remembered this because if the items on that list of queries could be somehow pinned to the defined DB Connections, this could also be used for displaying those session settings. Actually, using this everyone could define which settings they are interested in, if any (or anything else the user wants, as long as it can be distilled down to a single value).
|
|
| Thu Mar 11, 2021 2:40 pm |
  |
|
SysOp
Site Admin
Joined: 26 Nov 2006
Posts: 7963
|
|
| |
|
I'm trying to get my head around what you are describing, and would like to ask for some additional details.
You say, quote good luck running it on an SQL Server without casting the actual value column for each row,
|
|
SELECT 'my value name' AS value_name, 'xyz' AS actual_value
UNION
SELECT 'my other value name' AS value_name, 2 AS actual_value |
The above might be in too simplified format for me to fully understand what the difficulty is. What about the following solution?
Create somewhere
|
|
CREATE TABLE table_results(row_id INTEGER IDENTITY, value_name VARCHAR(100), actual_value SQL_VARIANT) |
in the Initialization section TRUNCATE that table.
in tests instead of using SELECT, use INSERT to insert results into the above table, note the use of SQL_VARIANT
Somewhere else at the end
|
|
SELECT value_name, actual_value
FROM table_results
ORDER BY row_id
|
Another option might be using generic data type casing to XML, conceptually like
|
|
SELECT ... AS value_name,
CAST((SELECT actual_value FOR XML PATH('')) as XML) AS _actual_value
UNION
... |
The above abstracts completely from the actual data type using generic to XML conversion. Hopefully I'm making sense here.
Last edited by SysOp on Sat Mar 13, 2021 11:40 am; edited 1 time in total |
|
| Fri Mar 12, 2021 8:36 am |
|
|
gemisigo
Joined: 11 Mar 2010
Posts: 2170
|
|
| |
|
The difficulties came gradually. First, we had a test case for which several developers created a few (dozen) queries to check different results/states/whatever in the database. Some of those were multi-row-multi-column but many single-row-single-column.
Writing
|
|
SELECT t.column1 FROM table AS t;
|
is easy.
So everyone wrote their test queries that way. After having to switch back and forth between 40 result tabs multiple times we tried to concatenate those we could. And that was kinda the top of the slope.
Writing
|
|
SELECT t.column1 FROM table AS t
UNION
SELECT t2.column2 FROM table AS t2
|
is still easy, but pretty much useless, and had to be changed to
|
|
SELECT 'value1 name' as value_name, t.column1 as value_value FROM table AS t
UNION
SELECT 'value2 name', t2.column2 FROM table AS t2
|
Much less easy and a few people started complaining. Adding new queries to the list became a nuisance. "So what?", I said, "you only have to do it once and you spare yourself the annoying search for the value you want to see". Well, once per test, but I didn't tell them that :)
So the code became a bit larger and quite a bit less readable. But it worked on MySQL and the tests become slightly faster. And then we tried the same concept on SQL Server where it failed miserably. I tried to make it easier for myself by using snippets to transform the SELECT part using a cast to varchar and it worked (sort of) but the test code was no longer easily portable between MySQL and MSSQL. I didn't even think about using sql_variant. Perhaps using a table would have been a viable workaround but no non-feature related writes were allowed (some benchmarks were run in the background then, that's no longer a requirement) and some testers had no other permissions but SELECT. Although that could be worked around by using temporary tables instead.
Doesn't the SQL Preprocessor have an #import directive? I recall seeing something similar but cannot make it work. Moving those annoying one-value to a separate tab/file where they can be UNION-ed without any interference and still being able to execute them together with the more complex test queries would be a tremendous help. It would make the whole test more readable. Hmm, it also could implement the display of the session settings almost as a side-effect. But I cannot make it work. Actually, not even the #def seems to work. I remember it had a separate pane but simply cannot bring it forth. It's not in the View or Context Menus. The only thing I've found is the Advanced Text Processor.
|
|
| Fri Mar 12, 2021 11:37 am |
|
|
SysOp
Site Admin
Joined: 26 Nov 2006
Posts: 7963
|
|
| |
|
Thank you for more details. I'm sorry for being a pain, but may I ask for a screenshot or something demonstrating visually the test workflow you are doing? I'm still struggling with understanding how this is being used. I mean where you look at the test results, and how they appear. The part that I understand least, is where you run the SELECT ... UNION ... SELECT... query. For now I'm guessing you created one big unit test, kind of an umbrella, in which you have many test cases, and in the very last test case that runs at the end of the unit test you added that SELECT ... UNION ... SELECT... query. If that is the case, using a results table sounds like cross platform solution. If not everyone has write permissions, maybe they need a stored procedure granted to public which everyone can execute Am I on the right path?
SQL Preprocessor's main use case is conditional code execution. For example, we are using it now more and more in the Schema Compare queries to execute database version specific code, and other similar cases where code depends on parameters, and versions, to reduce the number of query permutations and simplify their maintenance. An example is below for Oracle, enabling the same query to be reused with Oracle versions before and after 11G, for one or more schemas or for a single table depending on the parameters provided.
|
|
SELECT
owner AS "Schema name",
table_name AS "Table name",
partitioning_type AS "Partition type",
DECODE(subpartitioning_type, 'NONE', '', subpartitioning_type) AS "Subpartition type"
-- #if dbver('11')
, "INTERVAL" AS "Partition interval",
DECODE("INTERVAL", NULL, NULL, def_tablespace_name) AS "Partition tablespace",
CASE WHEN def_subpartition_count > 0 THEN def_subpartition_count END AS "Subpartition count"
-- #endif
FROM all_part_tables
WHERE
-- #if('$OBJECT_NAME$' = '')
(owner IN ($SCHEMA_NAMES$))
-- #else
(owner = '$SCHEMA_NAME$') AND (table_name = '$OBJECT_NAME$')
-- #endif
ORDER BY 1, 2
|
|
|
| Sat Mar 13, 2021 12:03 pm |
|
|
SysOp
Site Admin
Joined: 26 Nov 2006
Posts: 7963
|
|
| |
|
Just a couple of thoughts here...
What if instead of executing a query to return the results of their test case, you ask developers to provide a SQL query for the same... It's a string that can be saved along with the test case name. You can run all their queries at the end of the unit test, or later. Perhaps develop a nice looking report that you or somebody else can run after all and share the results with the team. The queries can be merged using SELECT... UNION... or not, in some stored procedure you maintain, which could use platform specific syntax and dynamic SQL, but that would be in just one central place. For developers they need not worry about all that, within their test case they need to provide text of a valid SQL query which gets saved into an internal table, internally that gets logged and timestamped, etc... Moreover, they can use different unit tests and unit test projects if they wish. As long as they follow the same naming and coding conventions you can get everything saved to that table in a way that would enable you to run test results aggregation report, as well as track historical progress and regression analysis.
Similarly to the above, you can use the existing project scope settings to make SA save test case results with details to a table and then optionally aggregate and email them. This is completely cross platform solution, data type conversion is taken care off in the unit tests framework, it saves results converted to text (similar to what you see in the pane for the messages that are logged when executing SQL code. Developers could add their "SELECT 'my value name' AS value_name, xyz AS actual_value" to the test cases itself. A test case doesn't have to be a single SQL query, it can be a SQL batch that the database can understand, kind of "Run this; Run that;" Developers would need INSERT permissions for the output table, but that's about it, that can be be granted to PUBLIC if managing many users is too much.
|
|
| Sat Mar 13, 2021 12:32 pm |
|
|
gemisigo
Joined: 11 Mar 2010
Posts: 2170
|
|
| |
|
I'm afraid we're not on the same page here. I'm not talking about doing tests by using the Unit Testing.
Unit Testing is a great feature for some simple repeatable tests but its usability rapidly decreases when things get a bit less simple and gets completely useless very soon after. For example, you can use it to check the resulting database state for stored procedures that manipulate (delete/insert/update) data, and that works like a charm. For data retrieval with procedures, you might get some mindful happiness in SQL Server, in case you only have stored procedures that return one result set. You can do INSERT INTO ... EXECUTE usp_... there and can do checks on that table. If they return more than one result set, you're out of luck. In the case of MariaDB, that "out of luck" part started when I said "data retrieval with procedures".
And even that only works for localized tests. It cannot be done with integration tests. We cannot combine test results from different systems because the one unit test project allows one connection. Well, we could actually, but that would require allocating even more resources that we cannot afford now.
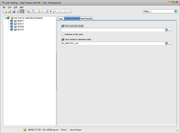
I don't believe a single screenshot would do it any justice, but here it is:

The screenshot above shows the number of result sets we have to check for a single test case for the process of selling a ticket for a journey, downloading it to a vehicle, and then validating said ticket onboard a vehicle (eg. a bus or a coach). I count them to be somewhere around 60. Approximately 2/3 of them is a multi-row-multi-column result set or result sets, coming from SELECT or CALL procedure statements. The rest is either a single-value or unions of single values like the one shown in the screenshot. We have several test types like this. Also, these tests cannot be prepared in advance as the identifiers are generated on-the-fly as the test starts. So, what we are doing is selecting a subsequent subset of the queries in the editor as the test phases progress and then visually compare the results returned by those queries to the results we expect. Occasionally some extra queries are added to the existing ones, either temporarily or permanently.
The scratchpad I suggested would not remedy this problem, it would only ease the pain it causes (scratch the itch, if I may say) by reducing the number of result sets we have to scan through. The only "ultimate solution" I could imagine would require rethinking a rather large part of the Unit Testing feature and I am not sure you'd even want to hear about that, because the current version works well for simple stuff.
|
|
| Sun Mar 14, 2021 1:52 pm |
|
|
SysOp
Site Admin
Joined: 26 Nov 2006
Posts: 7963
|
|
| |
|
Thank you very much for more details.
May I ask what's your ultimate goal? Do you want to eyeball results of each step to validate them, or compare them to previous results and check for regressions?
Getting and saving results including multiple result sets of a procedure isn't an issue, saving multiple results with different column types or number of columns is fairly easy too. Perhaps I can suggest how to get all that output saved to a single flat file, or to a table with XML column that can accomodate any result set and multiple too. But what's the use of that? Don't you need to "feed" the results of previous steps to consecutive steps? What does it do for you?
If I can understand your objectives, I hope I might be able to contribute to finding a good solution. I'm afraid I still don't understand it.
|
|
| Sun Mar 14, 2021 6:21 pm |
|
|
gemisigo
Joined: 11 Mar 2010
Posts: 2170
|
|
| |
|
The ultimate goal is... was... The ultimate goal was to be able to write composite tests that could be used to test the validity of the designed and implemented database objects (tables, constraints, views, functions, and ultimately procedures and processes) and to be able to reuse those tests to ensure that validity remaining intact after changes. That is definitely impossible to achieve while adhering strictly to the boundaries of SQL. Even the reduced form (unit tests?) does not promise much success when it comes to stored procedures. So far I was unable to find a single environment/application that succeeded in making unit tests by the simple method of defining expected result sets and then comparing them somehow (equality, non/equality, inclusion, intersection, whatever, etc.) to the actual result sets (or subsets of those). I've seen a few good tries, eg. tSQLt, but that one is limited to T-SQL and hence to SQL Server.
So I put the bar lower and lower and now I'm looking for a "good enough". And that "good enough" is already pretty undemanding. I've shown a small part of the basic solution: if we cannot make SQL to compare the result sets for us we have to do it ourselves. The problem is that there are so many of those result sets and they are separated into so many small pieces. And that "context switching" between the tabs is annoyingly slow. Also, the attention/comparison of the human automatons tends to wear out quickly. Writing the results to files would provide no advantage. We still couldn't compare the results automatically and removing the data from the server to another medium only hinders the testing/validating process.
Sure, we could combine some of the result sets into a common one but doing that is what requires extra resources we would like to spare (I mean, use elsewhere). That's why I'm looking for a way to automatize that combination process. So far the best method seems to be the one you suggested by pushing everything possible to a single table and check its contents periodically. And then you suspected right, there is the issue that some queries might need the intermediate results of earlier ones.
I'm afraid there isn't a really good solution. Noone has created one yet. Even goodenoughs are rare. But perhaps I can put (erm, botch?) together something of acceptable quality by pouring extra effort into it.
|
|
| Tue Mar 16, 2021 1:56 pm |
|
|
SysOp
Site Admin
Joined: 26 Nov 2006
Posts: 7963
|
|
| |
|
I think I better understand now. My 2 cents... you describe functional testing rather than narrow specification testing (for this input, I get this output). From my experience for the former you would need a full time QA engineer, there are no cheap solutions for a complex system with waterfall logic. A good testing solution requires significant investment, both time and resources wise. Either a QA engineer or a developer would need to work on that. Unit tests can be simple for a small function or complex with waterfall. QA engineers can develop scripts implementing limited scope workflows, like submitting a request to book a trip using stored procedure "A", getting id or token created by that request and passing it to the next test step like requesting payment details, if they are stored, then calling procedure "B" to retrieve them, else calling procedure "D" with test parameters to create a dummy credit card payment, and then calling stored procedure "E" for issuing a ticket, and so on... That kind of run-test script needs to know all the details for what to expect from upstream and what to send to downstream procedures. If I were given a task like that, I think I would create separate QA schema in the database with whatever tables are necessary for my unit tests to save state data and retrieve it in the follow up tests. My test cases would know where to pickup previous outputs and what do with them. For a portable cross-platform application I would save that data in XML format. XML enables me to store data of any shape and with any number of result sets. But even using XML I'm afraid I can't avoid developing platform specific code to build and to parse the XML to do it on the database side. If that must be a platform agnostic solution, an external tool or script would be required.
|
|
| Wed Mar 17, 2021 1:56 pm |
|
|
gemisigo
Joined: 11 Mar 2010
Posts: 2170
|
|
| |
|
"A picture is worth a thousand words", the adage says, doesn't it? Let me try again:

What you described, and what I was talking about that above, an integration test. That would take exactly as you said, time and effort, and other resources as well (QA engineer, developers, etc.). The difference is, that you think my goal is to write such a test. And that's false. My goal is to write composite tests for integration tests. Not the integration tests themselves, but composite tests for it. Minor parts of the integration test.
Take a look at the picture. I only care about the stuff that's in the green field/red rectangles. Those are my responsibility. Everything else is not. Those other parts have their respective owners of responsibilities. I only have to make sure my parts work perfectly. Of course, that could be achieved the way you described (QA engineers, XML, etc.) but that's sluggish and cumbersome. Or the simple tests (the unit tests) could be combined/concatenated into composite tests (that's what I was talking about, that's what my original goal was) and used to build the DB part of the integration tests. This would be much simpler and easier than wasting efforts on almost-project-level-development of the integration tests. One could create a bunch of unit tests they would do anyway, and then combine them using the Unit Testing feature of SA, where they could turn on/off the different tests or test cases as needed:

This could be a simple way. Everything that happens in the DB should have a way to be checked/validated/compared in the DB, without moving the stuff outside of the DB, keeping it in the DB, where it's easy to build generic processes for checking/validation. But there isn't. I can create unit tests for stored procedures that insert/update/set/delete from the database without having to leave the DB. For some unknown (and moronic) reasons there's no way to create units for stored procedures that yield result sets, without having to involve external apps. I cannot call a stored procedure and make it store the result sets it produces back into the database. SQL Server can do it with the first result set but nothing beyond that. MySQL/MariaDB cannot do it even with the first one. The parts marked orange refuse to cooperate when designing unit tests. (More precisely, I cannot do such things unless explicitly specified and done in the stored procedure itself, but that would harm a great many things including readability, performance, side-effects, etc., meaning that's not really an option).
As a result, there is no means to keep this in the DB. But there could be a way to make it easy by moving it back into the DB as soon as possible. Except that no one is doing it. I've found no app or environment that chose this path. Everything I've run into like tSQLt, MyTAP, and a couple of others I cannot remember, is either incomplete or overcomplicated and a pain in the back to use. And that's very strange because every DB developer environment is already halfway there without having to change anything at all. They already display that data. It only takes one more step.
For example, Unit Testing in SA has five tabs, three of which are actually executing SQL queries. Each of them can execute queries and I guess, each of them also gmoets the result sets, but it is only important for the Execute tab, as that's where the value for the Check tab is produced, even if it's only the first column of the first row of the first result set that is returned in the Execute tab. At a first glance, checking for a single result value would be overly simplistic, but it is definitely true, that for an arbitrarily complex and complicated set of result sets (and states) it is possible to write a bunch of CASE...WHENs that return when-this-then-this-error, when-that-then-that-failure, ELSE Ok (when every type of error "fails"). It might be "as hard as a rock and as dumb as a brick" but works very well. Until it turns out that the following statement is only true "for an arbitrarily complex and complicated set of result sets", that is available for testing. And that's what the result sets of the stored procedures are not. They are simply not available for examination. And that's the reason I have to move even the most basic unit testing of those from the Unit Testing to the plain "execute and eyeball the results" method. It's slow, it's hard, but it works (mostly). In exchange, it frequently causes false positives and false negatives and takes extra care (that is, it wastes resources).
There could be a stupidly simple solution for this. If the Initialize tab would push every result set it gets back into the DB then that data would instantly be available for all kinds of scrutiny. It could be done by creating (temporary?) tables and inserting the result rows there, following some naming pattern, eg. rs1, rs2, or really, whatever, it should be cleaned up after the test anyway.
Yes, I know, this is simple from my point of view only. It definitely takes time and effort to create it, but it would be a generic, one-size-fits-almost-all, and would only have to be done once. Without this certain unit tests (sadly, a large number of them) cannot be done in DB.
|
|
| Sun Mar 28, 2021 6:50 pm |
|
|
SysOp
Site Admin
Joined: 26 Nov 2006
Posts: 7963
|
|
| |
|
I really appreciate the effort you made to explain your requirements with such level of details. I actually know couple of solutions for the "orange" issue.
1. This can be can considered somewhat cross-platform, kind of. You may still dislike it, because it would result in somewhat stretching the green area and doing something outside of plain SQL. It's possible to write a loopback CLR function in SQL Server or a UDF in MariaDB to execute a procedure in the database (or any arbitrary SQL query) , enumerate its result sets, convert them to generic XML, and save them back to some QA table in the same or different database. Moreover, with sufficient effort this can be made more or less universal, accepting some delimited string with parameters, and the procedure name, parsing parameters, executing dynamic SQL, and enumerating the results converting each to XML and saving to a results table where they saved values can be then checked using an additional SELECT statement or something in the consecutive steps. I think checking the saved results for valid values or invalid values is more or less trivial.
So the CLR first. Here is some basic example I found on the web after a bit of googling.
https://social.msdn.microsoft.com/Forums/sqlserver/en-US/da5328a7-5dab-44b3-b2b1-4a8d6d7798b2/insert-into-table-one-or-multiple-result-sets-from-stored-procedure?forum=transactsql
In theory, the sky is the limit, everything can be generified, number of results, parameters, columns in the resultsets, etc... It's just a question of how much code to put in that CLR function.
for (int tableOrdinal = 0; tableOrdinal < results.Tables.Count && tableOrdinal < tableList.Length; ++tableOrdinal
Conceptually writing similar MariaDB UDF is the same, it just requires more coding as it has to be done in low level C/C++ where one needs to take care of the database connection, memory allocation and deallocation, etc... Here are some examples
https://github.com/mysqludf/lib_mysqludf_skeleton
https://pure.security/simple-mysql-backdoor-using-user-defined-functions/
In both cases for an experienced CLR/UDF developer it would require about a day of coding to develop a fully functional POC version.
2. And here is a completely generic database type independent method, not requiring changing anything in the database, not needing additional code compilers and debuggers, not needing to deploying compiled files to the database server (as in MariaDB UDF case). I'm talking about developing a plugin in SQL Assistant using the preinstalled plugin IDE. For example, if we choose Pascal language for the plugin, something like the following can be done
|
|
with Connection do
begin
if Execute( SQL ) then
begin
// loop by tables returned
for t := 0 to DataTables.Count - 1 do
begin tbl := DataTables[t];
// loop by rows
for r := 0 to tbl.RowCount - 1 do
begin
// loop by columns
for c:= 0 to tbl.ColCount - 1 do
begin
val := VarToStr( tbl.Cells[c, r] ); // returns any value as string
... do something with the value
end;
end;
end
// save whatever we want back to the database
Execute( 'INSERT INTO ......' )
end; |
Even though it doesn't require much code, I'm afraid you won't like this method too, because it's like building your own unit testing solution. It won't work from within the unit tests, and so you would also need to make this plugin to read some instructions for what it needs to execute, which is again a non SQL stuff.
What I can do for you here is to submit an enhancement request for implementing a new feature allowing saving result sets of a unit test in whichever "shape" or quantity they come to a user defined table in some generic XML or JSON format.
|
|
| Mon Mar 29, 2021 8:54 pm |
|
|
gemisigo
Joined: 11 Mar 2010
Posts: 2170
|
|
| |
|
And I'm grateful for your tolerance for my rantings and patience for my frequent stubbornness. I'm also sorry for you having to read my lengthy monologues but my greatest fear in life is being misunderstood and it happens rather often. That's why I tend to try and put in as much detail as I can. I usually overdo it (eg. right now), but every now and then even that's not enough.
Regarding the possible solutions for my problem, I checked the links you provided, and you see, that's what I'm talking about. Even among those who tried, no one was going to go down the easy path. As if they were afraid of the dark side, or I don't know what... :) And when they manage to keep things in the database it stops being simple. Those are not database-based solutions. Those are programmer people's solutions that use the database for solving specific problems and those specific problems weren't exactly analog to mine. Besides, I have a generic problem. Thousands of them, actually. They require generic solution method(s), not specific ones that have to be constantly and specifically adjusted for each problem. Furthermore, if I understand correctly, some of them would not only need adjustments made to the solution, they'd also require changes applied to the problem itself (see #6 below).
The methods you suggest would possibly work, but there are several issues with them:
1. They require deploying/installing things to the servers we may not have the required privileges to do. Though this is only a minor issue, and sometimes it can be done, but I've already been frowned upon for installing Ola Hallengren's maintenance routines. They were not allowed. Now that was some crazy requirement for a development server...
2. You said "experienced CLR/UDF developer it would require about a day of coding". I have my (based on decades-long experience) doubts there, but I'm always willing to give the benefit of the same. So let's suppose, it would be so. One problem with that one is that we lack experienced CLR/UDF programmers. Actually, not only do we also lack inexperienced CLR/UDF programmers, unfortunately, we have no developers with any level of experience in that area at all. However incredible that may be, we have always managed to get away without having to do those things so far. End of the road of that luck, it seems.
3. They provide solutions to SQL Server and MariaDB using two different methods, that is, we should implement two ways of doing that. That's development and resource allocation for two different projects. We still have no way to do it in Postgres, Oracle, MySQL, and SQLite. Of those four SQLite "luckily" lacks the feature of stored procedures and everything can be unit tested in SA's Unit Testing. MySQL is very similar to MariaDB so that could be count as one (though there always appear to be a small number of differences that need to be addressed). Hence it only leaves us with Postgres and Oracle that, again, might or might not be able to use the same or similar solution, meaning that in the best-case scenario those are three separate projects that have to be designed, implemented, supported, and waste time upon in other different ways. Might be a tiny nuisance for a multinational corporation that has teams for implementing homebrew solutions, but it would be quite a strain and drain on resources for our small company.
4. By converting everything to XML it removes the relational data from its native state in which it is easy to check (almost the same as the initial problem by moving the stuff outside of the database). That conversion alone introduces points of possible failure.
5. Doing the type of checks needed for the comparison (inclusion, exclusion, overlap, value checks, range checks, etc.) is easy in SQL (that's the language made for data handling after all). Doing the same things for XMLs is very far from trivial, quite difficult in some cases (alas, I have some bad experiences there), and it requires programming stuff. As such, it would also remove the independence of the database developers from the people doing the programming. Except, of course, they are the same person, which might or might not be the case (for us, sadly isn't).
6. I'm not sure I understood correctly, but it appears that it would also require changing the original calls (the "accepting some delimited string with parameters, and the procedure name, parsing parameters, executing dynamic SQL" part you mentioned). While that looks to be trivial, it still does introduce additional points of failure.
I don't assume I could get an allocation of resources for those issues already visible, let alone the ones we don't know might be there. Heck, even I wouldn't approve that, and I'm the one needing it.
In contrast, the solution I guess would work requires four things:
1. The result sets themselves and their table structure. I guess the result set format (columns and their types) is provided with the result set, for example, it's available in SQL Editor (I know I can hover the cursor over a column and it tooltips its type). I suppose that's the same in other products as well since they do display the results. Most of them anyway.
2. Ability to CREATE TABLE. That's readily available for all RDBMSs, and they are basically the same everywhere, "because of the SQL standard" :) The possible (syntax) differences are usually minuscule, much smaller than the difference between CLR and UDF in SQL Server and MariaDB, for example.
3. Ability to INSERT INTO those table(s). It's analog to #2, not much to develop here either.
4. The processing of the above three the way you described in the SA plugin code snippet. As I see it, everything required is already possible with the plugin. Well, everything except making it work in Unit Testing.
After that, all the required checks can be done in SQL, without having to BS the data around into (other) external apps, XML, etc. Tolerably clean, if I may say so, compared to part 1, with no extra juggling of the results around, other than that absolutely necessary (rerouting it back into the database into corresponding tables). It is also largely compatible with the different RDBMSs as it doesn't use anything related to specific RDBMSs like the already mentioned CLR or the UDF.
Please, do not waste time making unit tests saving the result sets into XML or JSON. If it wouldn't work outside of unit tests (and it wouldn't help much there either), I don't believe that feature would be used much. Those formats are inadequate for comparison without a considerable amount of additional effort and will not provide any advantages over simply displaying the result sets in a grid. It is already possible to export the contents of a grid into xls files which can be compared with existing tools (by moving things out of the DB, again).
I'll take a look at the plugin but I'm afraid of it being a dead-end too.
By the way, why saving it to a table in XML/JSON? That seems to be almost as much (or even more) hassle than saving it in its original format.
|
|
| Tue Mar 30, 2021 6:24 pm |
|
|
SysOp
Site Admin
Joined: 26 Nov 2006
Posts: 7963
|
|
| |
|
I have discussed this internally. We can easily save results from test cases to a table, tag them with unique id, time and test case name. Show them if necessary after the execution, but it would be up to user to develop "final check" test case to peer into the results table and evaluate what's saved there, and raise an error if they are unsatisfactory. That would complete the unit test and make it succeed or faill if an error is raised. Saving multipe resultsets into an XML value wouldn't be an issue, that's a piece of cake.
Do you think that would help to solve the problem? Or still would be insufficient?
|
|
| Wed Mar 31, 2021 11:51 am |
|
|
SysOp
Site Admin
Joined: 26 Nov 2006
Posts: 7963
|
|
| |
|
Sorry, I missed your last question. XML and similar formats enable us to save any results. We can handle single or multiple results sets with any number of records, persistent or variable columns, it makes no difference to us as we don't cater to any specific output structure or format.
We already support optional feature Enabling logging statuses of all test cases to a table. An additional column in that table can be added and used for saving the outputs of each test case, regardless of the "shape" of their output and the number of results sets. The logging table is updated in real time after each test case executing. This enables consecutive test cases to query the table and analyze previous results. It solves your dilema with stored procedures returning multiple result sets and variable result sets, they get all flattened and can be used in post-validation, as well as to to retrieve inputs for the following steps. By post validation I don't mean post mortem. I mean that test case B is able to analyze the output of test case A regardless of how many results are returned from that step and processed based on what if finds in the results.
|
|
| Thu Apr 01, 2021 5:52 pm |
|
|
SysOp
Site Admin
Joined: 26 Nov 2006
Posts: 7963
|
|
| |
|
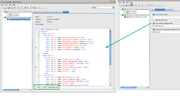
Here is a small proof of concept to visualise the proposed solution. Logging all tests run statuses to a database table feature isn't new. What's new here is a new column added to that table for storing actual rows returned. That data is saved in real time and available to all consecutive test cases if they need it to obtain input parameters as well as for final analysis to verify if the ultimate end result is in line with the initial input parameters. For easy of use results of each test case can be shown on screen as a set of individual tables, as many as returned by the executed test script or procedure, or as a unified XML, which is what gets saved for each test. What do you think? Would it help to solve the issues you are facing?
|
|
| Fri Apr 02, 2021 3:43 pm |
|
|
|
|
You cannot post new topics in this forum
You cannot reply to topics in this forum
You cannot edit your posts in this forum
You cannot delete your posts in this forum
You cannot vote in polls in this forum
|
|
|
